2017-07-25 - Collections as Data: IMPACT
Below are some rough notes from the Library of Congress Collection as Data: IMPACT conference on 2017-07-25. #AsData
https://blogs.loc.gov/thesignal/2017/07/collections-as-data-impact/
Edward Ayers
Gathering the power of collections.
“We live in history the way we live in oxygen.” It’s all around us.
Sarah Hutton
Fantastic artwork. Wonderful star maps using fasteners of WW1 Canadian military records.
Stephanie Stillos
Rosenwald curator at LOC. Historian turned librarian.
Exploring the history of a 15C book. How it survived censorship, traveled from reader to reader.
Shoutout to Ben Schmidt’s visualization of MARC records.
Stephen Robertson
Place data hard to understand in textual form.
Web mapping made this more accessible to people. No longer need the GIS person.
Robertson says Digital Harlem owes its form to Google Maps.
Key sources for this to get beyond political and artistic elites - black newspapers - records of the Manhattan district attorney - sources full of information about where things happened
Robertson wanted to map the sources.
GIS still too complex to analyze the qualitative data historians. Thanks to Google Maps and the team, launced Digital Harlem in 2009 as a web based form of mapping.
Visualization are generous, rich, browsable to reveal the scale and complexity of data, and display a context and aid analysis of data. Not possible in Digital Harlem to offer access to the sources in which the site draws, but does not prevent the creation of data from those sources: events, people, places.
Those of us in the twentieth century encounter problems of access to sources: we need to talk about more about how restirctions to sources shape the kind of projects we can create.
Recording details of every location and event in legal records and newspapers. Far more spatial data in newspapers than we’re use to thinking about.
Organize inforamtion into a data model, into a database, and geocoded.
“Mining” sits awkwardly with humanities scholars concernecd with empathy. Sets up a sense of creating data as dehumanizing. Mapping data can help mitigate this sense. An appreciation of context and vulnerability (citing Nowviskie).
Mapping data seen in its geographical context: enriched, historical map layer (real estate altas). Historic maps fill in the spaces on a street map – dividing Harlem into smaller and smaller places and how they interact.
Maps give context, humanize data.
Maps bring disparate things together. Geospatial web helps bring together the rythms of everday life.
How blacks develop spaces separate from whites as they flock to Harlem. But it’s only a partial map of commercailized leisure. Also add dance halls, theaters, pool rooms, basketball courts, boxing bouts. And also add non-commercial leisure: churches, fraternal lodges, community organizations, social clubs.
You get a complex map highlighting fundamentally how a small segment of leisure and night life appears.
Also, events: numbers of arrests. Gives the research new focus. The pervasiveness of gambling.
Also, individual lives: but assembling enough data was beyond their resources. But did generate maps for a handful of people about residence, work, leisure, parole records. Lives not bounded by the neighborhood. That the Census data we rely on, ultimately only tells us where they slept. The geography of male laborers vs. female laborers often very different. Paired with a timeline to see how these lives evolved. Living in the city is not living in the neighborhood.
Also the ability to visualize your own maps in Digital Harlem: the capacity highlights how the maps are exploratory, not illustrative. Making sense of the data and sources inside.
Sites that are research tools for people who understand the data, vs. sites that are sheared and aimed at those who are not experts.
Linear maps like Storymap don’t tell you the complexity of projects. The timeline in Digital Harlem is also a shortcoming. Neatline does a lightly better job of displaying complexity and simultaneous events. Annotate waypoints, attached to polygons and lines, draw attention to analysis of space. Proximity, connections, etc. Annotation shift some of the argument to visual form. The future direction in visualizing data in using maps is the capacity to dynamically integrate maps and narratives. To put data into context.
Rachel Shorey
Collaboration between journalists and software engineer.
“once upon atime the open government data was in an adversarial format”
Github repository at the WaPo (Stephen Rich) cleaning up election filing. Collaborations from news nerds from various sources. Back end data collaboratively managed. Found issues with the filings.
“once upon a time the structured data was hiding”
NYTimes has more programmers on staff than any other newsroom.
Jessie Daniels
Extremists in the archives.
Work started before the web, exploring how white supremacy changed when things moved online.
Understanding student search patterns and how they might sumble upon white supremacist websites.
Pair sites with white supremacist sites and civil rights sites & LOC sites.
Students were very savvy about the way websites looked when evaluating sites.
Paul Ford
Bloomberg open sourced What is Code.
Archives cannot be escaped.
All of our software problems are legacy problems. Archive is a nice way of saying “legacy.”
“the writing process is stochastic”
“nested procrastination” – wrote a CMS to manage his books

Ford’s procrastination.
Writers aren’t learning good practice. He built a timeline.
“The text boxes need to get smarter.”
Wants to get as much cultural information into events as he can with Unscroll (personal side project).
Writer’s block is a sense of the writer’s own sense of fradulence.
How cultural information comes out:
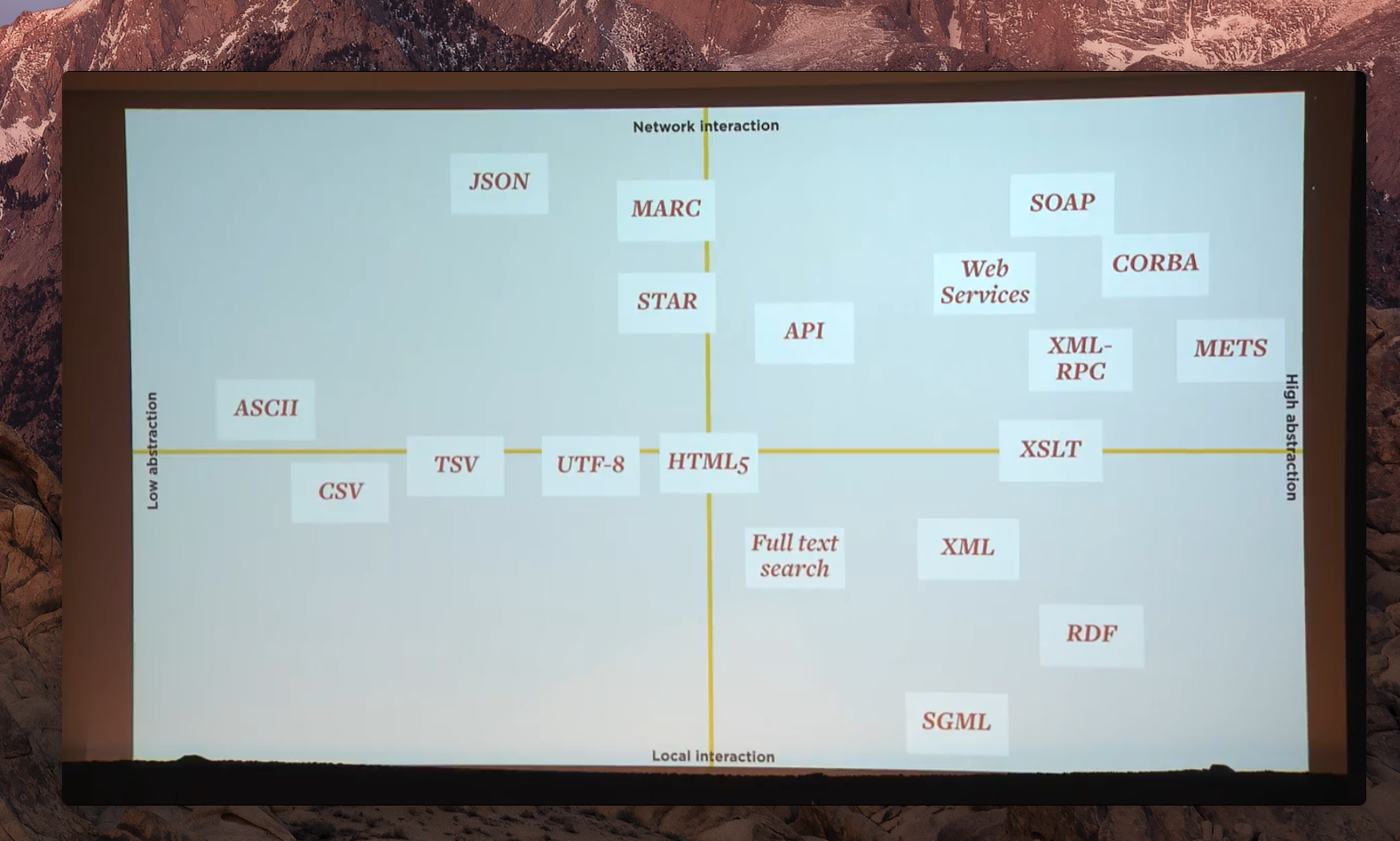
Paul Ford’s identification of how cultural data comes to us.
It’s really hard to work with.
Cooper Hewitt (all on Github; but many many files)
The Met - giant CSV file, hard to work with
“This is me criticizing the commons.”
Wayback API wonderful but terrible.
Wikipedia: horrible to work with. The XML is an endless nightmare of pain.
25 million MARC records at LOC. Want’s to spider everything, but there’s no good way to do so.
Tension between archive and access. An open archive is good enough, but… SQL? What about relational databases?
SQLite – public domain, its on all of your phones, built in everywhere. Part of Python. 105K SQL database. It runs the world and is powerful and unassuming. But if you put all your data into SQLite databases – I could download them and search them and explore them without having to put it anywhere in five seconds.
Also, make them torrentable! Don’t get rid of the APIs or get rid of anything. But port your stuff over – a professional imprimatur signal to port data to SQLite? Supplement, not replace!
“SQLite will rule the world.”
Make data available on BitTorrent, in SQLite. Can software help resolve that gap? Release corpora as BitTorrent!
Two fallacies: - Publisher’s fallacy: archives are free content - Archivist fallacy: news is an archive waiting to happen
“It takes an unbelievable amount of work to get value and meaning out of an archive.”
Software to resolve complicated relationships between archives, news, actual use.
Nick Adams
Berkeley data science institute
New methods for old documents
Well-structured research-ready data: machine readable, queryable, retain original structure, supplemental annotation that are searchable, linked to other data describing the same objects
Using Jupyter notebooks to explain whats happening.